| |
| ホーム | 概要 | 組織 | 研究 | 教育 | 活動 | アーカイブ | |
 |
環境ゲノミクス |
[ English | Japanese ] |
|



 |
  |
 |
京都大学 化学研究所
バイオインフォマティクスセンター
教授
阿久津 達也 |
ゲノム情報解析のためには様々な情報技術が必要となるが、我々は情報技術の中でもアルゴリズムを中心に研究を行っている。具体的には、配列検索、タンパク質立体構造予測、生物情報ネットワークの解析および予測、化学構造・糖鎖構造の情報解析などを対象に、高速かつ柔軟なアルゴリズムの開発を目標に研究を行っている。また、最近では、生物情報ネットワークの構造や遺伝子発現データの動特性などの数理的解析も行っている。
生物情報ネットワーク構造の数理解析
最近の研究により代謝ネットワーク、タンパク質相互作用ネットワークなどの生物情報ネットワークが「スケールフリー」と呼ばれる共通の数理的性質を持つことがわかってきた。また。そのようなネットワークを生成する各種の数理モデルも提案されている。我々も代謝ネットワークの構造や遺伝子発現量の分布に関するスケールフリー性の数理的解析を行っている。その成果の一つとして、化合物を頂点とした基質ネットワークが P (k )∝k -γというスケールフリー則に従う場合、化合物もしくは酵素を頂点とした反応ネットワークは P (k )∝k -γ+1というスケールフリー則に従うというスケールフリー性の変換則を発見した(図1)。さらに、バイオインフォマティクスセンターで開発しているKEGGデータベースを用いて調べたところ、実際のデータにおいても、この変換則が近似的に成立することを確認した。
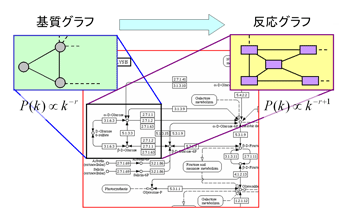 図1 代謝ネットワークにおけるスケールフリー性の変換則
図1 代謝ネットワークにおけるスケールフリー性の変換則
サポートベクターマシンを用いた配列・化学構造解析
サポートベクターマシンと呼ばれる統計的情報解析手法がバイオインフォマティクスにも有効に適用されつつある。サポートベクターマシンを有効に適用するためには、対象間の類似度を測るカーネル関数を開発することが必要となるが、我々は配列間および化学構造間の類似度を測るカーネル関数を開発している(図2)。本研究において開発した化学構造に対するカーネル関数を、化合物の活性や毒性の推定などに適用した結果、既存のカーネル関数と少なくとも同程度の分類精度を持ちながら、数十倍高速に動作することが判明した。
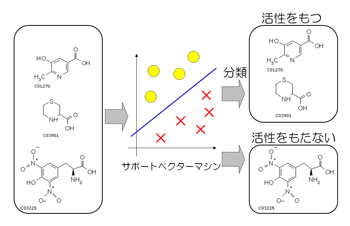 図2 サポートベクターマシンを用いた化合物の活性の推定
図2 サポートベクターマシンを用いた化合物の活性の推定
|
|平成19年度|平成18年度|平成17年度|平成16年度|平成15年度|
※平成17年度より「環境ゲノミクス」へ移動 |
