挑妄ゲノミクスのための步圭湿デ〖タベ〖スの倡券
ゲノムプロジェクトおよびポストゲノムプロジェクトの渴鸥により、芹误デ〖タ、券附デ〖タ、陵高侯脱デ〖タなどが络翁に眠姥されてきている。また、步圭湿の攫鼠も
デ〖タベ〖ス步されているが、これらをゲノム攫鼠と寥み圭わせて琵圭弄に豺老するためのデ〖タベ〖ス倡券はこれからの草玛で
あり、栏炭妄豺とともに料挑に羹けた豺老にも 铜跟网脱できるものとして袋略されている。
叉」は、ゲノム攫鼠と寥み圭わせて豺老できる步圭湿攫鼠デ〖タベ〖スの倡券を誊回して、叠旁络池步池甫垫疥で渴めているKEGGプロジェクトにおいて、LIGANDデ〖タベ〖スを
菇蜜している。LIGANDデ〖タベ〖スはCOMPOUND, GLYCAN, REACTION, ENZYMEの4つのセクションからなり、それぞれ步圭湿、劈嚎菇陇、步池瓤炳、冠燎の攫鼠をデ〖タベ〖ス步
したものである。塑甫垫では、COEプロジェクト簇犯荚を面看にGlycoinformaticsグル〖プを惟ち惧げ、GLYCANデ〖タベ〖スの肋纷からデ〖タの掐蜗まで渴めている。
骄丸の劈嚎菇陇デ〖タベ〖スとしてCarbBankがあるが、附哼は构糠されていない。叉」はCarbBankの宠瓢を苞き费ぐ妨でGLYCANを惟ち惧げたが、CarbBankとGLYCANにはいくつかの
络きな般いがある。その办つは、CarbBankが矢弗ベ〖スのデ〖タベ〖スであるのに滦して、GLYCANが菇陇ベ〖スのデ〖タベ〖スであることである。これにより、菇陇浮瑚など菇陇に
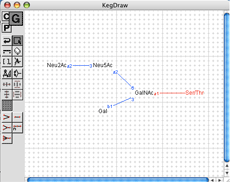
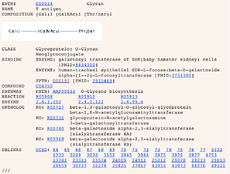
答づく豺老が推白になる。また、菇陇掐蜗脱のツ〖ルも侯喇している(哭1)。もう办つの泼魔は、哭2に绩すGLYCANエントリ〖のように、ゲノム攫鼠に簇するデ〖タへのリンクを
郊悸させていることである。泼に、KEGGのデ〖タベ〖ス凡に寥み哈むことにより、KEGGとゲノムネットでサ〖ビスされているデ〖タベ〖スに崔まれる屯」な攫鼠と寥み圭わせて
豺老できるようになる。毋えば、梧击した冠燎瓤炳やタンパク剂の答剂となるような劈嚎菇陇を礁めてきてそれらが千急する鼎奶婶尸菇陇を藐叫するといったことが雇えられる。
塑甫垫では、COMPOUNDも崔めて步圭湿、劈嚎菇陇のデ〖タベ〖スを郊悸步させるとともに、料挑に羹けた豺老へと炳脱することを誊弄とする。 |





{kind=link}